The PDF processor makes it possible to handle PDF documents, and convert them into different formats. This can be helpful when extracting the text substance of PDF documents to analyze them, create vector embeddings, or use them as input to other NLP models.
🖨️ Converting to Text
To use this middleware, you import it in your CDK stack and instantiate it as part of a pipeline.
💁 The below example takes PDF documents uploaded into a source S3 bucket, and converts them to plain text.
import { S3EventTrigger } from '@project-lakechain/s3-event-trigger';import { PdfTextConverter } from '@project-lakechain/pdf-text-converter';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { const cache = new CacheStorage(this, 'Cache');
// Create the S3 event trigger. const trigger = new S3EventTrigger.Builder() .withScope(this) .withIdentifier('Trigger') .withCacheStorage(cache) .withBucket(bucket) .build();
// Convert uploaded PDF documents to plain text. trigger.pipe(new PdfTextConverter.Builder() .withScope(this) .withIdentifier('PdfTextConverter') .withCacheStorage(cache) .withSource(trigger) .build()); }}Converting Documents
The PDF processor makes it possible to specify a specific task to be performed to the middleware. By default, as seen in the previous example, the PDF processor converts the entire document to plain text. However, you can specify a task to convert the document to a different format. Below is a table describing the supported output types for document level.
| Output Type | Description |
|---|---|
text | Convert the entire document to text. |
image | Convert the entire document as a JPEG image. |
💁 In the below example, we convert an entire PDF document as a stitched image containing all pages of the document.
import { PdfTextConverter, ExtractDocumentTask } from '@project-lakechain/pdf-text-converter';
const pdf = new PdfTextConverter.Builder() .withScope(this) .withIdentifier('PdfTextConverter') .withCacheStorage(cache) .withSource(source) .withTask(new ExtractDocumentTask.Builder() .withOutputType('image') .build() ) .build();Layout Detection
The ExtractDocumentTask supports layout detection to detect the number of tables and images present across the entire PDF document, these information are added as metadata to the output documents. To enable layout extraction, you use the withLayoutExtraction method.
import { PdfTextConverter, ExtractDocumentTask } from '@project-lakechain/pdf-text-converter';
const pdf = new PdfTextConverter.Builder() .withScope(this) .withIdentifier('PdfTextConverter') .withCacheStorage(cache) .withSource(trigger) .withTask(new ExtractDocumentTask.Builder() .withOutputType('text') .withLayoutExtraction(true) // 👈 Enable layout extraction .build() ) .build();📄 Extracting Pages
In addition to being able to process an entire PDF document, the PDF processor can act on the page level, rather than on the entire document.
💁 In the below example we configure the PDF processor to extract each pages from the PDF document as a separate document, and forward each of them to the next middlewares in the pipeline.
import { PdfTextConverter, ExtractPagesTask } from '@project-lakechain/pdf-text-converter';
const pdf = new PdfTextConverter.Builder() .withScope(this) .withIdentifier('PdfTextConverter') .withCacheStorage(cache) .withSource(trigger) .withTask(new ExtractPagesTask.Builder() .withOutputType('pdf') .build() ) .build();By using the ExtractPagesTask, you can act on a page level and request the middleware to convert each pages to different formats. Below is a table describing the supported output types for each pages.
| Output Type | Description |
|---|---|
pdf | Convert each page to a PDF document. |
text | Convert each page to a plain text document. |
image | Convert each page as a JPEG image. |
Layout Detection
The ExtractPagesTask supports layout detection to detect the number of tables and images present in each page, these information are added as metadata to the output documents. To enable layout extraction, you use the withLayoutExtraction method.
import { PdfTextConverter, ExtractPagesTask } from '@project-lakechain/pdf-text-converter';
const pdf = new PdfTextConverter.Builder() .withScope(this) .withIdentifier('PdfTextConverter') .withCacheStorage(cache) .withSource(trigger) .withTask(new ExtractPagesTask.Builder() .withOutputType('pdf') .withLayoutExtraction(true) // 👈 Enable layout extraction .build() ) .build();📝 Parsing Method
Converting the content of PDF documents into plain text is a difficult exercise as the PDF format has been initially designed to be a display format optimized for printing. Therefore, PDFs typically contain vector graphics and text is not stored in a linear fashion.
To optimize the results, the PDF text converter implements a 3-step parsing method that we document below.
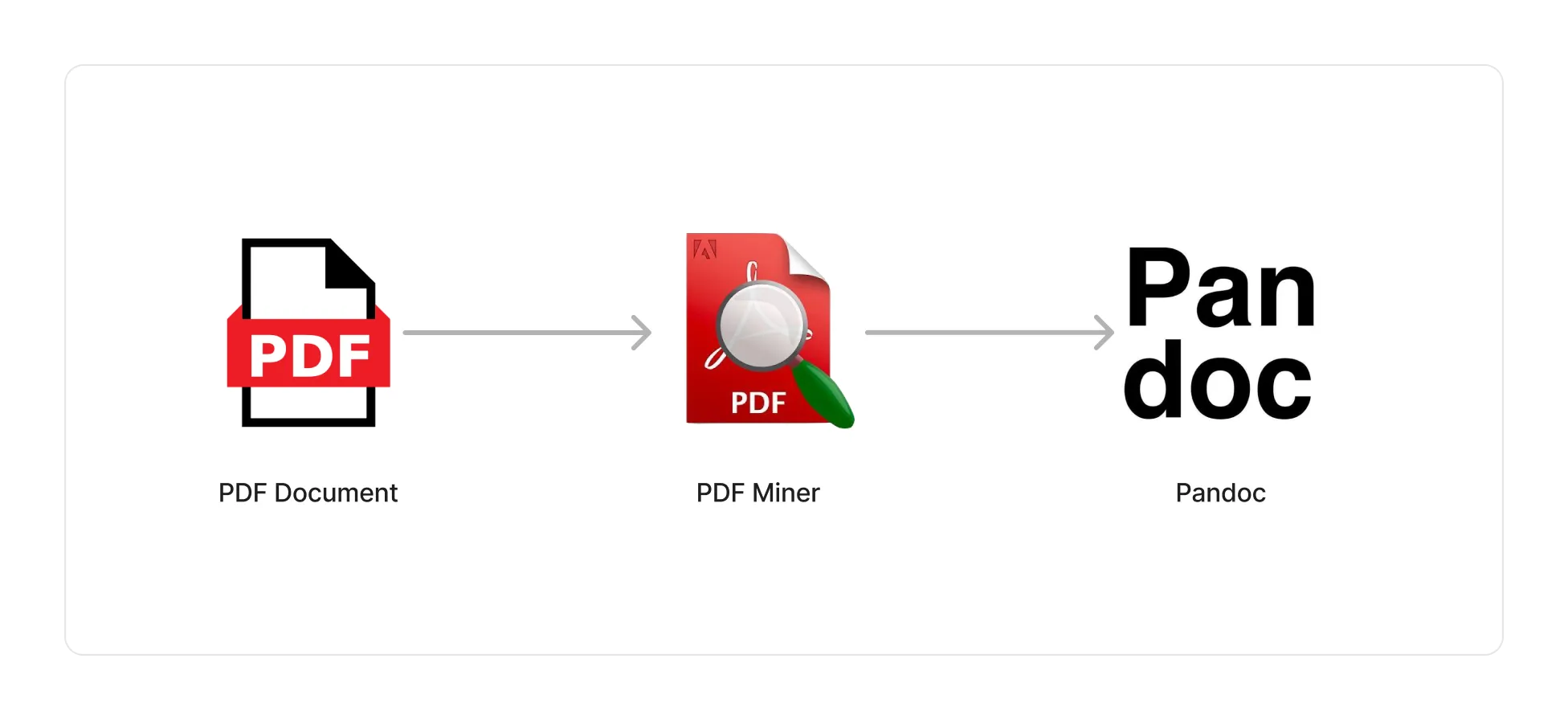
The first step is to extract the raw text out of the document using the pdfminer.six library. We then clean the text to remove invalid lines, and run the entire document through Pandoc to leverage its document formatting capabilities.
🏗️ Architecture
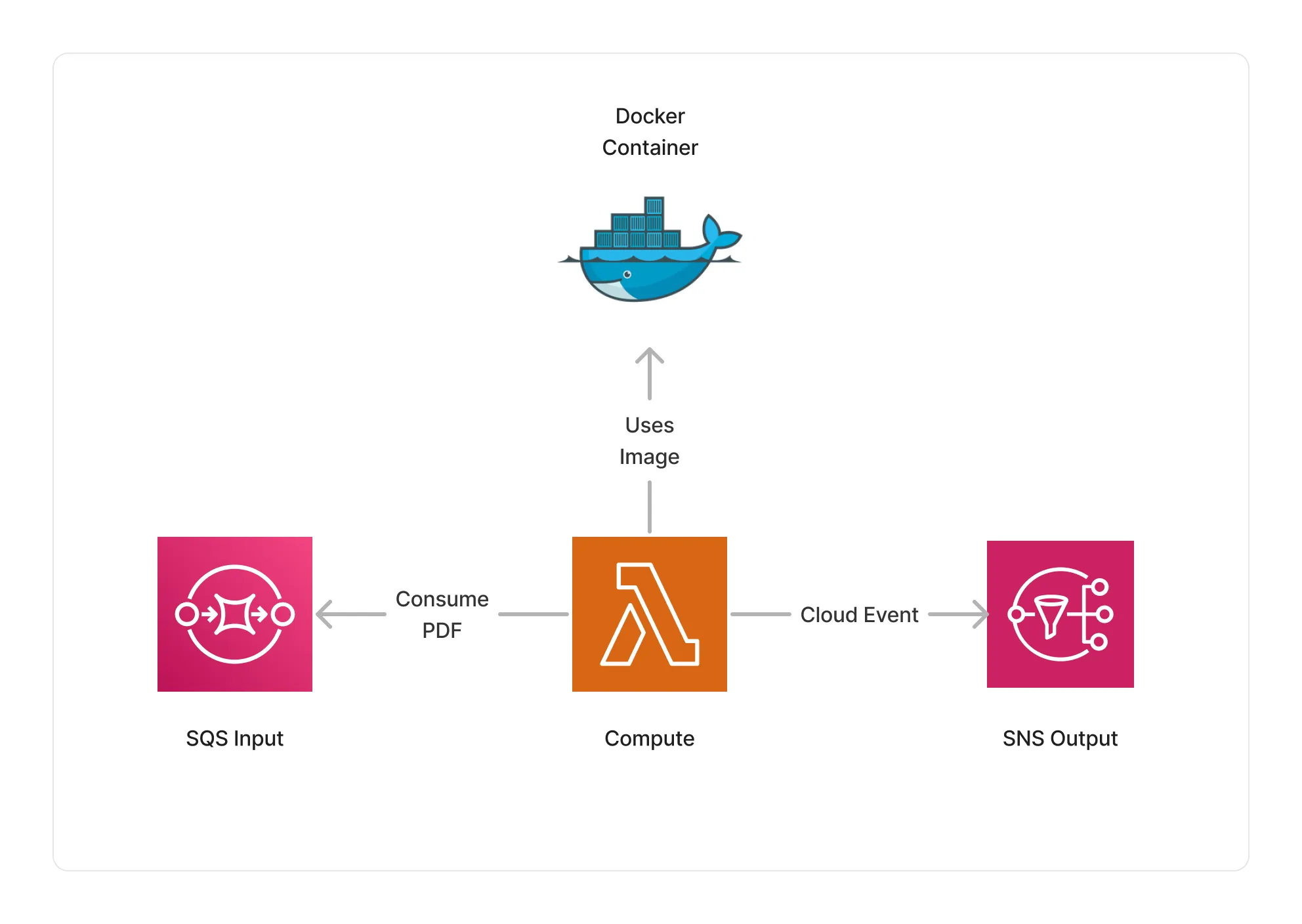
This middleware is based on a Lambda compute running the pdfminer.six library and Pandoc packaged as a Lambda Docker container.
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
application/pdf | PDF documents. |
Supported Outputs
| Mime Type | Description |
|---|---|
text/plain | Plain text if output type is text. |
image/jpeg | JPEG images if output type is image. |
application/pdf | PDF documents if output type is pdf. |
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
- Building a RAG Pipeline - End-to-end RAG pipeline using Amazon Bedrock and Amazon OpenSearch.
- PDF Vision Pipeline - A pipeline transcribing PDF documents to text using a vision model.