Bedrock
Unstable API
0.8.0
@project-lakechain/bedrock-embedding-processors
This package enables developers to use embedding models hosted on Amazon Bedrock to create vector embeddings for text and image documents within their pipelines. It exposes different constructs that you can integrate as part of your pipelines, including Amazon Titan, and Cohere embedding processors.
📝 Embedding Documents
To use the Bedrock embedding processors, you import the Titan or Cohere constructs in your CDK stack and specify the embedding model you want to use.
Titan Text
ℹ️ The below example demonstrates how to use the Amazon Titan embedding processor to create vector embeddings for text documents.
import { TitanEmbeddingProcessor, TitanEmbeddingModel } from '@project-lakechain/bedrock-embedding-processors';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { // The cache storage. const cache = new CacheStorage(this, 'Cache');
// Creates embeddings for input documents using Amazon Titan. const embeddingProcessor = new TitanEmbeddingProcessor.Builder() .withScope(this) .withIdentifier('BedrockEmbeddingProcessor') .withCacheStorage(cache) .withSource(source) // 👈 Specify a data source .withModel(TitanEmbeddingModel.AMAZON_TITAN_EMBED_TEXT_V1) .build(); }}Titan Multimodal
ℹ️ The below example demonstrates how to use the Amazon Titan embedding processor to create vector embeddings for images.
import { TitanEmbeddingProcessor, TitanEmbeddingModel } from '@project-lakechain/bedrock-embedding-processors';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { // The cache storage. const cache = new CacheStorage(this, 'Cache');
// Creates embeddings for input documents using Amazon Titan. const embeddingProcessor = new TitanEmbeddingProcessor.Builder() .withScope(this) .withIdentifier('BedrockEmbeddingProcessor') .withCacheStorage(cache) .withSource(source) // 👈 Specify a data source .withModel(TitanEmbeddingModel.AMAZON_TITAN_EMBED_IMAGE_V1) .build(); }}Embedding Size
When using the Amazon Titan multimodal embedding model, you can specify the size of the embeddings generated for the images using the .withEmbeddingSize API.
💁 The default embedding size is set to 1024, and valid sizes are 256, 512, and 1024. Note that embedding size customization is only available for Amazon Titan multimodal models.
import { TitanEmbeddingProcessor, TitanEmbeddingModel } from '@project-lakechain/bedrock-embedding-processors';
const embeddingProcessor = new TitanEmbeddingProcessor.Builder() .withScope(this) .withIdentifier('BedrockEmbeddingProcessor') .withCacheStorage(cache) .withSource(source) .withModel(TitanEmbeddingModel.AMAZON_TITAN_EMBED_IMAGE_V1) .withEmbeddingSize(512) // 👈 Specify the embedding size .build();Cohere
ℹ️ The below example uses one of the supported Cohere embedding models.
import { CohereEmbeddingProcessor, CohereEmbeddingModel } from '@project-lakechain/bedrock-embedding-processors';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { // The cache storage. const cache = new CacheStorage(this, 'Cache');
// Creates embeddings for input documents using a Cohere model. const embeddingProcessor = new CohereEmbeddingProcessor.Builder() .withScope(this) .withIdentifier('CohereEmbeddingProcessor') .withCacheStorage(cache) .withSource(source) // 👈 Specify a data source .withModel(CohereEmbeddingModel.COHERE_EMBED_MULTILINGUAL_V3) .build(); }}🌐 Region Selection
You can specify the AWS region in which you want to invoke Amazon Bedrock using the .withRegion API. This can be helpful if Amazon Bedrock is not yet available in your deployment region.
💁 By default, the middleware will use the current region in which it is deployed.
const embeddingProcessor = new TitanEmbeddingProcessor.Builder() .withScope(this) .withIdentifier('BedrockEmbeddingProcessor') .withCacheStorage(cache) .withSource(source) .withModel(TitanEmbeddingModel.AMAZON_TITAN_EMBED_TEXT_V1) .withRegion('eu-central-1') // 👈 Alternate region .build();📄 Output
The Bedrock embedding processor does not modify or alter source documents in any way. It instead enriches the metadata of the documents with a pointer to the vector embeddings that were created for the document.
💁 Click to expand example
{ "specversion": "1.0", "id": "1780d5de-fd6f-4530-98d7-82ebee85ea39", "type": "document-created", "time": "2023-10-22T13:19:10.657Z", "data": { "chainId": "6ebf76e4-f70c-440c-98f9-3e3e7eb34c79", "source": { "url": "s3://bucket/document.txt", "type": "text/plain", "size": 245328, "etag": "1243cbd6cf145453c8b5519a2ada4779" }, "document": { "url": "s3://bucket/document.txt", "type": "text/plain", "size": 245328, "etag": "1243cbd6cf145453c8b5519a2ada4779" }, "metadata": { "properties": { "kind": "text", "attrs": { "embeddings": { "vectors": "s3://cache-storage/bedrock-embedding-processor/45a42b35c3225085.json", "model": "amazon.titan-embed-text-v1", "dimensions": 1536 } } } }}ℹ️ Limits
Both the Titan and Cohere embedding models have limits on the number of input tokens they can process. For more information, you can consult the Amazon Bedrock documentation to understand these limits.
💁 To limit the size of upstream text documents, we recommend to use a text splitter to chunk text documents before they are passed to this middleware, such as the Recursive Character Text Splitter.
Furthermore, this middleware applies a throttling of 10 concurrently processed documents from its input queue to ensure that it does not exceed the limits of the embedding models it uses — see Bedrock Quotas for more information.
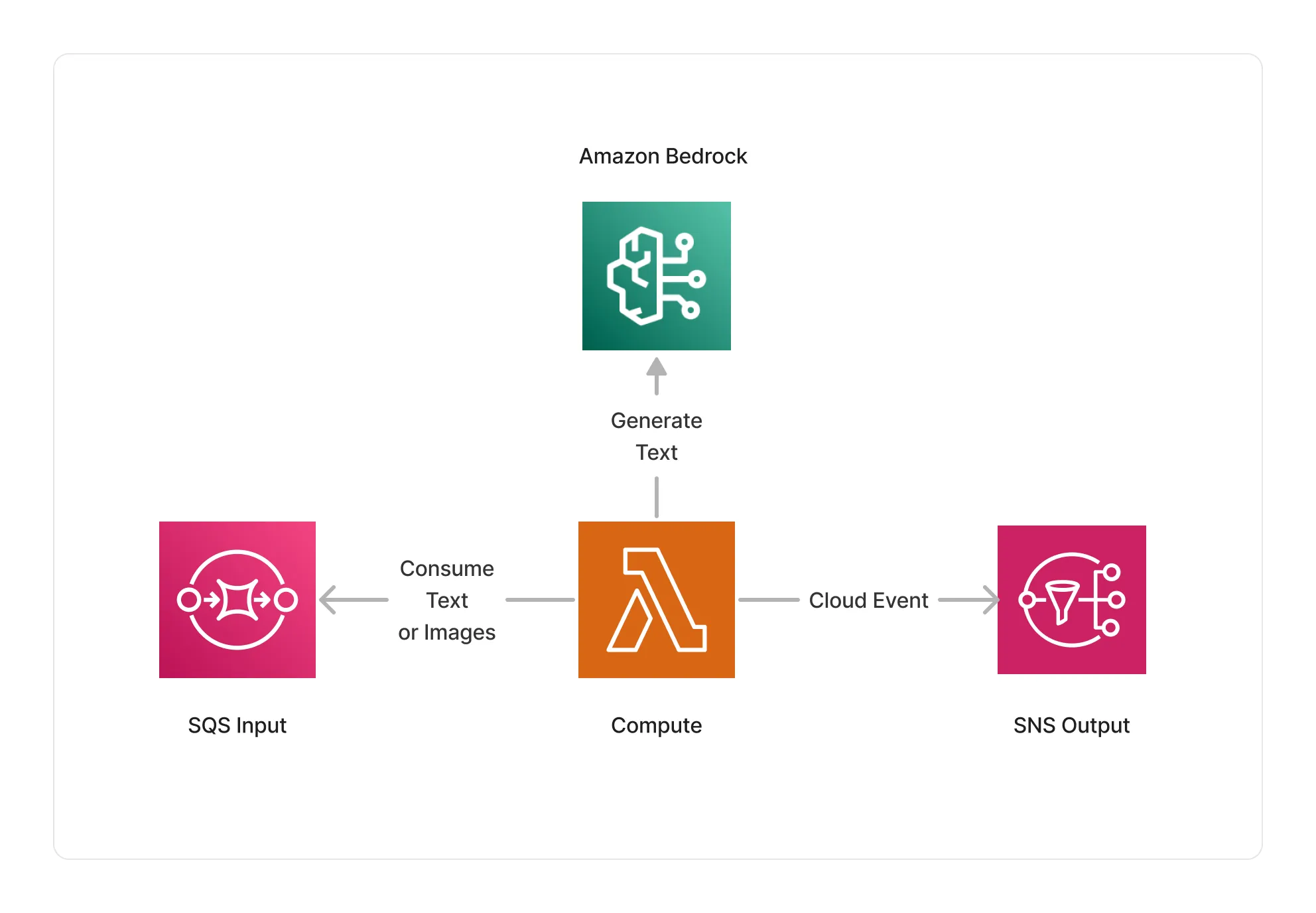
🏗️ Architecture
The middlewares part of this package are based on a Lambda compute running on an ARM64 architecture, and integrate with Amazon Bedrock to generate embeddings for text documents.
🏷️ Properties
Supported Inputs
The supported inputs depend on the selected model.
| Mime Type | Description | Model |
|---|---|---|
text/plain | UTF-8 text documents. | Amazon Titan Text, Cohere |
text/markdown | UTF-8 markdown documents. | Amazon Titan Text, Cohere |
image/jpeg | JPEG image documents. | Amazon Titan Multimodal |
image/png | PNG image documents. | Amazon Titan Multimodal |
Supported Outputs
The supported outputs depend on the selected model.
| Mime Type | Description | Model |
|---|---|---|
text/plain | UTF-8 text documents. | Amazon Titan Text, Cohere |
text/markdown | UTF-8 markdown documents. | Amazon Titan Text, Cohere |
image/jpeg | JPEG image documents. | Amazon Titan Multimodal |
image/png | PNG image documents. | Amazon Titan Multimodal |
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
- Bedrock OpenSearch Pipeline - An example showcasing an embedding pipeline using Amazon Bedrock and OpenSearch.
- Cohere OpenSearch Pipeline - An example showcasing an embedding pipeline using Cohere models on Bedrock and OpenSearch.
- Bedrock Multimodal Pipeline - An example showcasing an embedding pipeline using the Titan multimodal embedding model.