Text Transform
The Text transform processor operates on plain text documents and allows to perform operations on text such as string replacements, base64 encoding, and substring extraction.
This middleware supports semantic operations, meaning that it understands the metadata associated with documents to use them as context to perform operations on them. For example, it can leverage PII, Part-of-Speech or Named Entities from document metadata to apply transformations such as substring redaction.
📝 Transforming Text
To use this middleware, you import it in your CDK stack and instantiate it as part of a pipeline.
💁 In the below example, we redact Personal Identifiable Information (PII) from input documents. Note that PII information need to be made available before being processed by the text transform processor.
import { NlpTextProcessor, dsl as l } from '@project-lakechain/nlp-text-processor';import { TextTransformProcessor, dsl as t } from '@project-lakechain/text-transform-processor';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { const cache = new CacheStorage(this, 'Cache');
// Detect the PII in the text. const nlpProcessor = new NlpTextProcessor.Builder() .withScope(this) .withIdentifier('Nlp') .withCacheStorage(cache) .withSource(source) // 👈 Specify a data source .withIntent( l.nlp() .language() .pii(l.confidence(0.9)) ) .build();
// Redact PII from the text. const transform = new TextTransformProcessor.Builder() .withScope(this) .withIdentifier('TextTransform') .withCacheStorage(cache) .withSource(nlpProcessor) .withTransform( t.text().redact(t.pii()) ) .build(); }}Chaining transformations
You can chain operations to be applied on input text. In the below example, we first select a substring part of the text document, replace several words in it, and then encode it in base64.
import { TextTransformProcessor, dsl as t } from '@project-lakechain/text-transform-processor';
const transform = new TextTransformProcessor.Builder() .withScope(this) .withIdentifier('TextTransform') .withCacheStorage(cache) .withSource(source) .withTransform( t.text() .substring(0, 1024) .replace('hello', 'world') .base64() ) .build();🏗️ Architecture
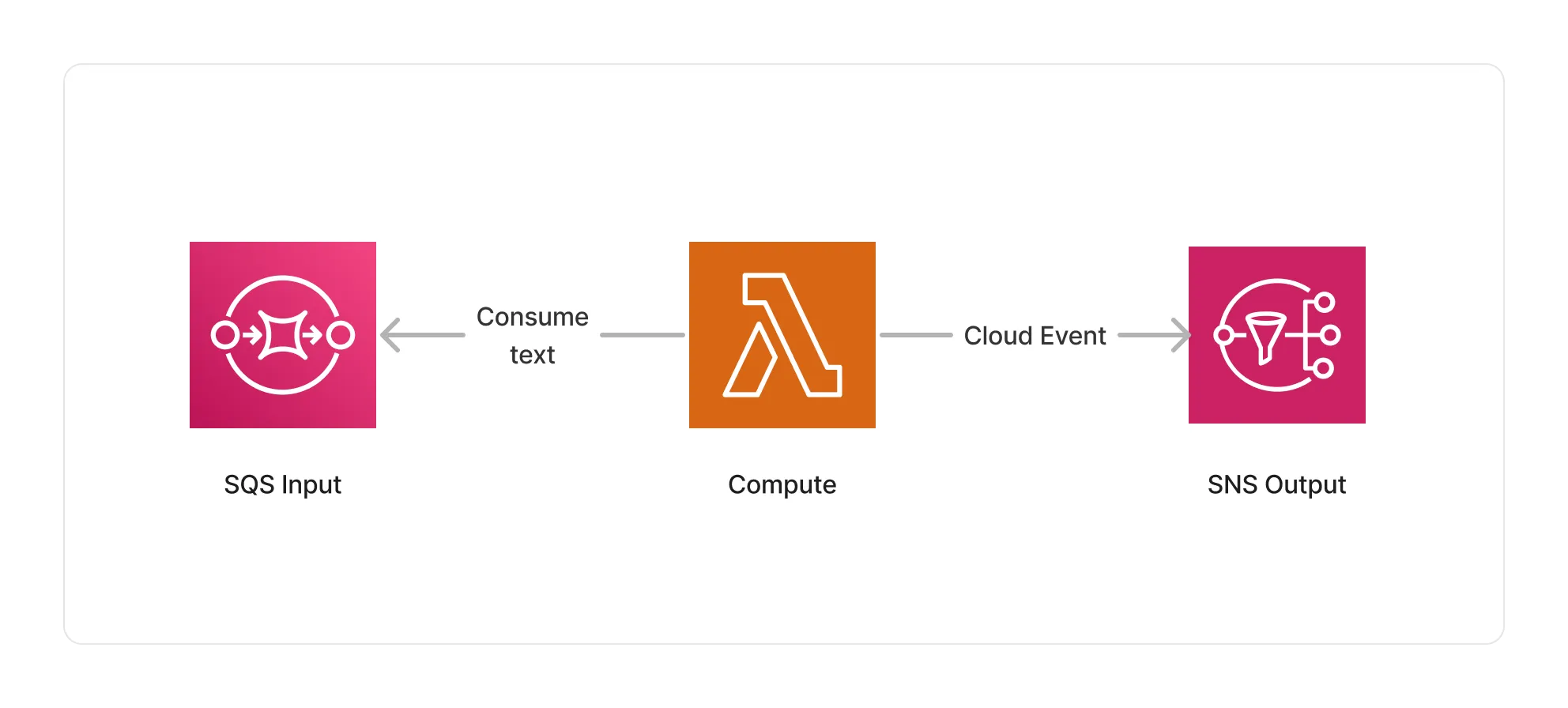
This middleware is based on a Lambda compute running the logic associated with the text transform processor.
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
text/plain | Plain text documents. |
Supported Outputs
| Mime Type | Description |
|---|---|
text/plain | Plain text documents. |
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
- PII Redaction Pipeline - A PII redaction pipeline using Project Lakechain.