Subtitle
The Subtitle processor allows to parse subtitles in the WebVTT and SubRip formats, and transform them into text or structured data. This allows you to process subtitle documents using other middlewares requiring pure text formats — for example, using the Translate middleware to translate subtitles into multiple languages.
It can also be a good choice when you need to format subtitles of various formats into a common JSON description, highlighting the attributes of each text block within the subtitles.
💬 Parsing Subtitles
To use this middleware, you import it in your CDK stack and instantiate it as part of a pipeline.
import { SubtitleProcessor } from '@project-lakechain/subtitle-processor';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { const cache = new CacheStorage(this, 'Cache');
// Create the subtitle processor, and define the desired output formats. const parser = new SubtitleProcessor.Builder() .withScope(this) .withIdentifier('SubtitleProcessor') .withCacheStorage(cache) .withSource(source) // 👈 Specify a data source .withOutputFormats('text') .build(); }}Output Formats
You can select the output formats that the subtitle processor will produce for each subtitle document using the .withOutputFormats method.
💁 If you select more than one output format, the subtitle processor will emit one document per output format. You can select between
textandjson.
const parser = new SubtitleProcessor.Builder() .withScope(this) .withIdentifier('SubtitleProcessor') .withCacheStorage(cache) .withSource(source) .withOutputFormats('text', 'json') // 👈 Output formats .build();📄 Output
The Subtitle processor supports extracting subtitles as plain text, or as structured JSON data. Below are examples of each output format.
Plain Text
The plain text format outputs the subtitles as new line separated text blocks, with each new line consisting of the \r\n\r\n characters. It is safe to assume that you can isolate each text block by splitting the text on those characters.
💁 Click to expand example
Welcome, everyone, to our annual gathering. As the clock strikes midnight, let us share our tales, the ones whispered in the shadows, the ones that dance with the stars.
I shall begin. It was a night much like this, under a crescent moon's embrace, when I ventured beyond the known paths. There, in the heart of the forest, I heard a voice, soft and melancholic, narrating the forest's ancient lore.
Intriguing, do continue. What did the voice speak of?
It spoke of ages past, of forgotten civilizations that once flourished beneath these very boughs. It told of joy, of sorrow, and of the eternal cycle that binds us all.JSON
The JSON format outputs each text block from the subtitles, as a common JSON description.
💁 Click to expand example
[ { "id": 1, "startTime": "00:00:00.000", "startSeconds": 0, "endTime": "00:00:10.000", "endSeconds": 10.0, "text": "Welcome, everyone, to our annual gathering. As the clock strikes midnight, let us share our tales, the ones whispered in the shadows, the ones that dance with the stars." }, { "id": 2, "startTime": "00:00:10.000", "startSeconds": 10.0, "endTime": "00:00:20.000", "endSeconds": 20.0, "text": "I shall begin. It was a night much like this, under a crescent moon's embrace, when I ventured beyond the known paths. There, in the heart of the forest, I heard a voice, soft and melancholic, narrating the forest's ancient lore." }, { "id": 3, "startTime": "00:00:20.000", "startSeconds": 20.0, "endTime": "00:00:30.000", "endSeconds": 30.0, "text": "Intriguing, do continue. What did the voice speak of?" }, { "id": 4, "startTime": "00:00:30.000", "startSeconds": 30.0, "endTime": "00:00:40.000", "endSeconds": 40.0, "text": "It spoke of ages past, of forgotten civilizations that once flourished beneath these very boughs. It told of joy, of sorrow, and of the eternal cycle that binds us all." }]🏗️ Architecture
This middleware is based on a Lambda compute based on the ARM64 architecture, using the node-webvtt and srt-parser-2 libraries to parse WebVTT and SubRip subtitles, respectively.
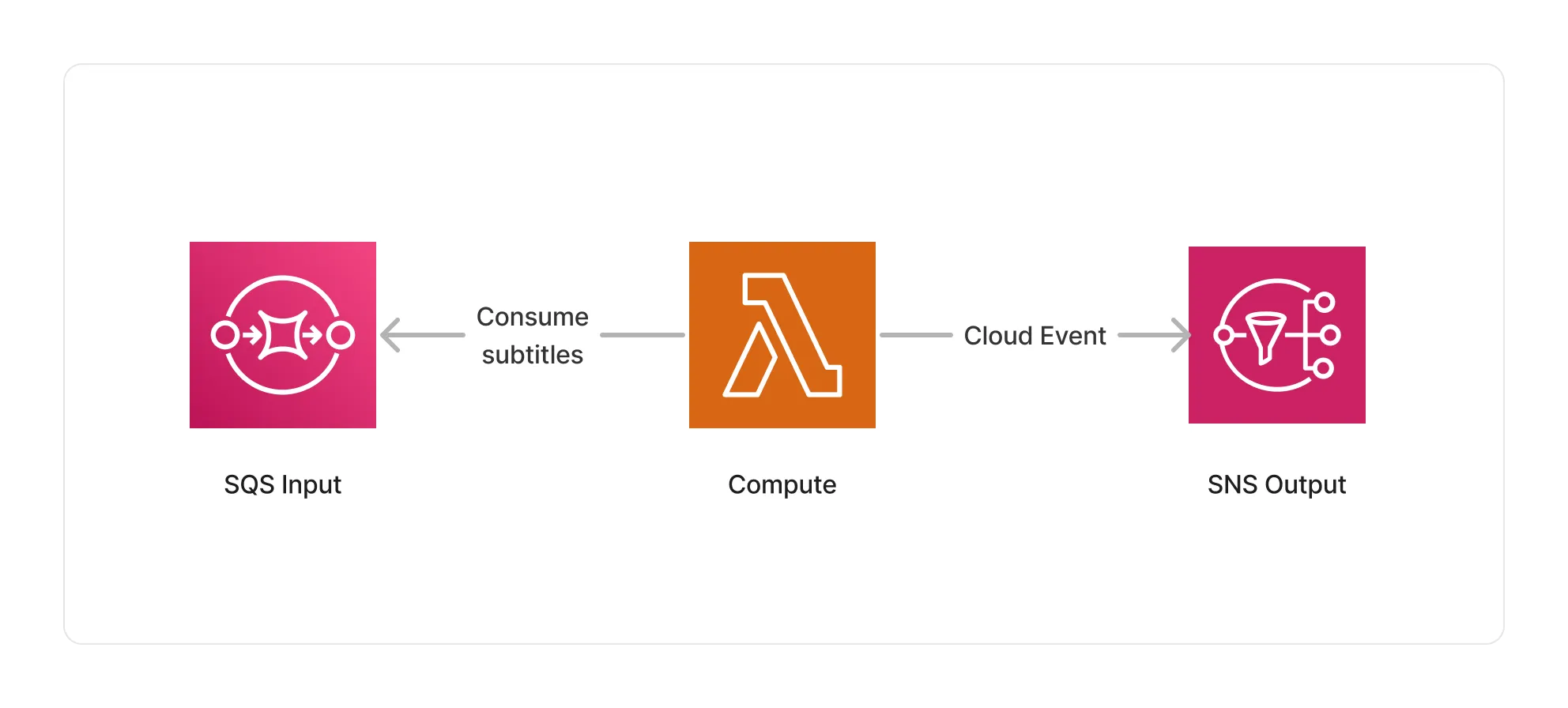
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
text/vtt | WebVTT subtitles. |
text/srt | SubRip subtitles. |
Supported Outputs
| Mime Type | Description |
|---|---|
text/plain | Plain text documents. |
application/json | JSON documents. |
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
Building a Video Subtitle Service - An example showcasing how to build a video subtitle service using Project Lakechain.